
Co-authors: Boran Car, Gaspare Vitta
Hermetic Build with Bazel: a case study
Since late 2021, we have been working with a BioTech customer to help them improve their CI setup with Bazel.
During this time, we managed to reduce CI duration from 25 minutes to under 5 minutes and saved our customers thousands of precious engineering hours.
In this series of articles, we will showcase our engagement with the customer: how we discover issues, how we monitored the Bazel build, and our solutions.
In part 1, we want to introduce you to the issues we faced.
Introduction
Executing a build two times and getting a bit-by-bit identical copy of all the artifacts is the holy grail of every Build Engineer.
There are many causes of non-determinism in today’s builds. The range spans from non-hermetic inputs (like compilers, third party dependencies, etc.) to internal randomness (some examples are timestamps, uninitialized values, etc).
Bazel can help you solve the non-determinism and achieve a hermetic build. Its philosophy is to build quickly, correctly, and reproducible. To get the best of it, you need to keep in mind how Bazel works and avoid certain anti-patterns that may affect your build.
Bazel build graph explained
A key concept to grasp while working with Bazel is how your code fits into the build graph and how your changes affect it.
Bazel models a build as a graph that is composed of 'nodes' and 'edges':
-
Each of the artifacts, such as a go executable binary or a tarball, makes the nodes.
-
Each of the actions (compile, test) produced an artifact (target) by combining zero or some other artifacts (dependencies), that made up the edges.
When you specify a target pattern to build, either //... or //foo/bar:my-binary, Bazel would parse up all the BUILD files and WORKSPACE to construct the relevant build graph in memory, then execute each of the actions orderly to produce the final output.
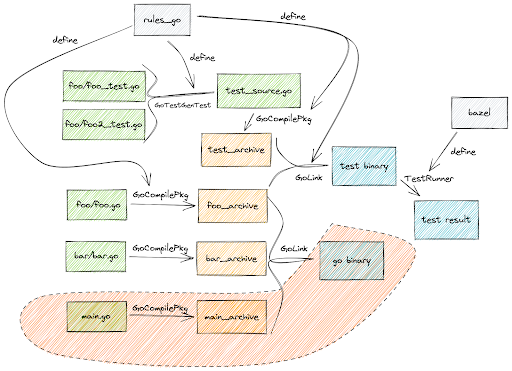
To speed up the build, Bazel operates under the assumption that when inputs of an action do not change, the output of the action will also remain the same. Under that assumption, Bazel caches all the artifacts and actions using their SHA256 hash as the cache key.
This makes portions of the build graph that are untouched by a change reusable between builds, thus speeding up the execution speed.
Knowing this we can start forming theories on what could be slowing down the build.
We'll need to understand which actions are happening and why?
How can antipatterns slow down a build?
When we started working with our customer, there was one thing that stood out: a large portion of the build graph was not being reused. On a fresh machine, if you were to execute bazel build //... twice, without changing anything, you would see that the second run would execute a lot faster than the first run, but there were still a lot of actions performed and new artifacts being produced.
This means that portions of the build graph which are closer to the leaf nodes were not reproducible.
Some actions produced inconsistent results even when there were no changes to the repository.
Another thing we noticed with our CI infrastructure setup, the 25 EC2 VMs running BuildKite Agent on Ubuntu 16.04, was that there was room for improvements since they were generating manual toil for the client’s team.
The bigger the non-reproducible artifacts got, the more disk space they were wasting.
Bazel was caching all of them, which necessitated frequent manual clean-ups. Not something we like doing.
Diving a bit deeper, we gained insight as to how a build is executed on these VMs.
The BuildKite agent is a systemd service (you can read more about systemd if you're not familiar - http://0pointer.de/blog/projects/systemd.html).
The agent pulls jobs from a BuildKite server and goes through the following steps:
-
A custom hook prepares the git repository with a clean checkout of the repo (at the revision to be tested)
-
BuildKite triggers the job's command, which ofter leverages a setup script to execute further commands
-
The setup script destroys all leftover containers from the last build
-
The setup script spins up a fresh Docker container with correct volumes mounted to the VM path
-
The setup script executes a build script using docker exec <fresh-container>
-
The build script setup various config before running gazelle, git lfs, and finally bazel test <flags> <targets>
One of the first observations is that we were killing and recreating the Bazel container with the test script steps.
This meant losing the entire Build Graph that Bazel was keeping in memory.
So, every time we were building, we were recomputing the entire build graph from scratch, checking every file and dependency.
If we can keep the container alive, we can benefit by only recomputing stuff that's changed...
Conclusion
This is the end of part 1. In today’s post we saw:
-
How bazel constructs its Build Graph,
-
How changes to the code can affect the cache in between builds,
-
Some common Bazel antipatterns
In part 2 we will dive into how we monitored the Bazel Build and how we established some baseline metrics that guided us in our work.